Real life Rest API Versioning for dummies

1 Once upon a time an API …
Once upon a time, the ACME Corporation was building a brand new IT product. It aimed at a new software to manage bookstores through a web interface and an API.
In the first steps, the developers drew up a first roadmap of their API based on the expectations of their first customers. They therefore built and shipped a microservices platform and released their first service contract for their early adopters.
Here is the design of this platform:
The High level design

More in depth

2 The platform and its roadmap
After shipping it into production, they drew up a roadmap for their existing customers to both improve the existing features and bring new ones.
As of now, we could think everything is hunky-dory isn’t it?
While engineers worked on improving the existing API, the sales representative have contracted with new customers. They enjoyed this product and its functionalities. However, they also ask for new requirements and concerns.
Some of them are easy to apply, some not.
For instance, a new customer asked the ACME engineers for getting a summary for every book and additional REST operations.
Easy!
However, last but not least, this customer would also get a list of authors for every book whereas the existing application only provides ONE author per book.
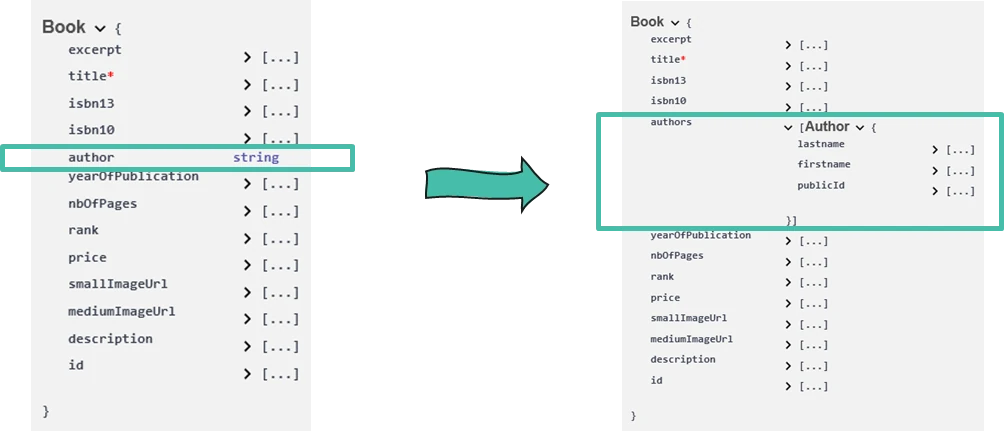
This is a breaking change!
A breaking change occurs when the backward compatibility is broken between two following versions.
For instance, when you completely change the service contract on your API, a client which uses the old API definition is unable to use your new one.
A common theoretical approach could be to apply versions on our APIs and adapt it according to the customer.
Unfortunately, the devil is in the details.
I will describe in this article attention points I struggled with in my last projects.
3 What to version? How and where to apply it?
After answering to the first question: Do I really need API versioning? you then have to answer to this new one: what should we consider versioning?
You only have to version the service contract.
In the case of a simple web application based on a GUI and an API

Versioning is applied in the service contract of your API. If you change your database without impacting the APIs, why should you waste your time creating and managing a version of your API? It doesn’t make sense.
On the other way around, when you evolve your service contract, you usually impact your database (e.g., see the example of breaking change above).
Moreover, the version is usually specified on the “middleware” side, where your expose your API. I’ll come back to this point in a later section.
If you want to dig into what is a breaking change and what to version, you can read this guide on the GitHub website.
3.1 How many versions must I handle?
Tough question!
Throughout my different experiences struggling with API versioning, the most acceptable trade-off for both the API provider and customer/client was to only handle two versions: the current and the deprecated one.
3.2 Where?
Now, you have to answer to this question: Where should I handle the version?
- On the Gateway?
- On Every Backend?
- On every service or on every set of services?
- Directly in the code managed by different packages.
Usually, I prefer manage it on the gateway side and don’t bother with URL management on every backend. It could avoid maintenance on both code and tests for every release. However, you can’t have this approach on monolithic applications (see below).
3.3 How to define it?
Here are three ways to define API versions:
- In the URL (e.g.,
/v1/api/books) - In a HTTP header (e.g.,
X-API-VERSION: v1) - In the content type (e.g.,
Accept: application/vnd.myname.v1+json)
The last one is now deprecated.
The RFC 9110 deprecates now custom usages of the accept HTTP header.
I strongly prefer the first one. It is the most straightforward.
For instance, if you provide your books API first version, you can declare this URL in your OpenAPI specification:/v1/api/books.
The version declared here is pretty clear and difficult to miss.
If you specify the version in a HTTP header, it’s less clear.
If you have this URL /api/books and the version specified in this header: X-API-VERSION: v1, what would be the version called (or not) if you didn’t specify the header? Is there any default version?
Yes, you can read the documentation to answer these questions, but who (really) does?
The version declared here is pretty clear and difficult to miss.
If you specify the version in a HTTP header, it’s less clear.
If you have this URL /api/books and the version specified in this header: X-API-VERSION: v1, what would be the version called (or not) if you didn’t specify the header? Is there any default version?
Yes, you can read the documentation, but who (really) does?
The first solution (i.e., version in the URL) mandatorily conveys the associated version. It is so visible for all the stakeholders and could potentially avoir any mistakes or headaches while debugging.
4 What about the main software/cloud providers?
Before reinventing the wheel, let’s see how the main actors of our industry deal with this topic. I looked around and found three examples:
4.1 Google
- The version is specified in the URL
- It only represents the major versions which handle breaking changes
4.2 Spotify
- The version is specified in the URL
- The API version is still
V1…
4.3 Apple
- The version is specified in the URL
- The API version is still
V1…
5 Appropriate (or not) technologies
In my opinion, technologies based on the monolith pattern don’t fit handling properly API Versioning. If you are not eager to execute two versions of your monolith, you would have to provide both of the two versions within the same app and runtime.
You see the point?
You would therefore struggle with:
- packaging
- testing both of two releases for every deployment even if a new feature doesn’t impact the deprecated version
- removing, add new releases in the same source code,… And loosing your mind.
In my opinion, best associated technologies are more modular whether during the development or deployment phases.
For instance, if you built your app with Container based (Docker, Podman, K8S,..) stack, you would easily switch from one version to another, and sometimes you would be able to ship new features without impacting the oldest version.
However, we need to set up our development and integration workflow to do that.
6 Configuration management & delivery automation
When I dug into API versioning, I realised it impacts projects organisation and, by this way, the following items:
- The source code management: one version per branch or not?
- The release process: How to create releases properly?
- Fixes, merges,…: How to apply fixes among branches and versions?
- The delivery process: How to ship you versions?
Yes it IS a big deal
Here is the least bad approach I think it works while addressing all of these concerns:
6.1 Source code configuration
When you want to have two different versions in production, you must decouple your work in several GIT (what else) branches.
For that, I usually put in place GitFlow.

source: Atlassian
Usually, using this workflow, we consider the develop branch serves as an integration branch.
But, now we have two separate versions?
Yes, but don’t forget we have a current version and a deprecated one.
To handle API versions, we can use release branches.
You can easily declare versions regarding your API versions.
For instance:
release/book-api-1.0.1release/book-api-2.0.1
We can so have the following workflow:
- Develop features in feature branches and merge them into the
developbranch. - Release and use major release numbers (or whatever) to identify breaking changes and your API version number
- Create binaries (see below) regarding the tags and release branches created
- Fix existing branches when you want to backport features brought by new features (e.g., when there is an impact on the database mapping), and release them using minor version numbers
- Apply fixes and create releases
6.2 Delivery process
As of now, we saw how to design, create and handle versions.
But, how to ship them?
If you based your source code management on top of GitFlow, you would be able now to deliver releases available from git tags and release branches. The good point is you can indeed build your binaries on top of these. The bad one, is you must design and automatise this whole process in a CI/CD pipeline.
Don’t forget to share it to all the stakeholders, whether developers, integrators or project leaders who are often involved in version definition.
Hold on, these programs must be executed against a configuration, aren’t they?
Nowadays, if we respect the 12 factors during our design and implementation, the configuration is provided through environment variables.
To cut long story short, your API versioning will also impact your configuration. Thus, it becomes mandatory to externalise it and version it.
You can do it in different ways.
You can, for example, deploy a configuration server. It will provide configuration key/values regarding the version. If you want a live example, you can get an example in a workshop I held this year at SnowcampIO. The configuration is managed by Spring Cloud Config.
You can also handle your configuration in your Helm Charts if you deploy your app on top of Kubernetes. Your configuration values will be injected directly during the deployment. Obviously if it’s a monolith, it will be strongly difficult.
Why?
Because you will lose flexibility on version management and the capacity on deploying several versions of your service.
7 Authorisation management
Here is another point to potentially address when we implement API versioning. When you apply an authorisation mechanism on your APIs using OAuthv2 or OpenID Connect, you would potentially have strong differences in your authorisation policies between two major releases.
You would then restrict the usage of a version to specific clients or end users. One way to handle this is to use scopes stored in claims.
In the use case we have been digging into, we can declare scopes such as: book:v1:write or number:v2:read to specify both the authorised action and the corresponding version.
For example, here is a request to get an access_token from the v1 scopes:
http --form post :8009/oauth2/token grant_type="client_credentials" client_id="customer1" client_secret="secret1" scope="openid book:v1:write book:v1:write number:v1:read"And the response could be:
{
"access_token": "eyJraWQiOiIxNTk4NjZlMC0zNWRjLTQ5MDMtYmQ5MC1hMTM5ZDdjMmYyZjciLCJhbGciOiJSUzI1NiJ9.eyJzdWIiOiJjdXN0b21lcjIiLCJhdWQiOiJjdXN0b21lcjIiLCJuYmYiOjE2NzI1MDQ0MTQsInNjb3BlIjpbImJvb2t2Mjp3cml0ZSIsIm51bWJlcnYyOnJlYWQiLCJvcGVuaWQiLCJib29rdjI6cmVhZCJdLCJpc3MiOiJodHRwOi8vbG9jYWxob3N0OjgwMDkiLCJleHAiOjE2Nz
I1MDQ3MTQsImlhdCI6MTY3MjUwNDQxNH0.gAaDcOaORse0NPIauMVK_rhFATqdKCTvLl41HSr2y80JEj_EHN9bSO5kg2pgkz6KIiauFQ6CT1NJPUlqWO8jc8-e5rMjwWuscRb8flBeQNs4-AkJjbevJeCoQoCi_bewuJy7Y7jqOXiGxglgMBk-0pr5Lt85dkepRaBSSg9vgVnF_X6fyRjXVSXNIDJh7DQcQQ-Li0z5EkeHUIUcXByh19IfiFuw-HmMYXu9EzeewofYj9Gsb_7qI0Ubo2x7y6W2tvzmr2PxkyWbmoioZdY9K0
nP6btskFz2hLjkL_aS9fHJnhS6DS8Sz1J_t95SRUtUrBN8VjA6M-ofbYUi5Pb97Q",
"expires_in": 299,
"scope": "book:v1:write number:v1:read openid book:v1:read",
"token_type": "Bearer"
}Next, you must validate every API call with the version exposed by your API gateway and the requested scope.
When a client tries to reach an API version with inappropriate scopes (e.g., using book:v1:read scope for a client which only uses the v2).
You will throw this error:
{
"error": "invalid_scope"
}8 And now something completely different: How to avoid versioning while evolving your API?
You probably understood that versioning is totally cumbersome.
Before putting in place all of these practices, there’s another way to add functionalities on a NON-versioned API without impacting your existing customers.
You can add new resources, operations and data without impacting your existing users. {: .notice–warning}
With the help of serialization rules, your users would only use the data and operations they know and are confident with. You will therefore bring backward compatibility to your API.
Just in case, you can anticipate API versioning by declaring a V1 prefix on your API URL and stick to it while it’s not mandatory to upgrade it.
That’s how and why Spotify and Apple (see above) still stick to the V1.
9 Wrap-up
You probably understood when getting into this topic that API versioning is a project management issue with consequences that requires tackling difficult technical ones. To sum up, you need to ask yourself these questions:
- Do I need it?
- Can I postpone API versioning by dealing with serialisation rules and just adding new data or operations?
- Is my architecture design compatible?
- Are my source code management and delivery practices compatible?
After coping with all these points, if you must implement API versioning, you would need to onboard all the different stakeholders, not just developers, to be sure your whole development and delivery process is well aligned with practice.
And I forgot: Good luck!