Déployer des batchs cloud native avec Spring Cloud Data Flow
Dans mon dernier article, j’ai tenté de faire un état des lieux des solutions possibles pour implémenter des batchs cloud natifs.

J’ai par la suite testé plus en détails les jobs et cron jobs Kubernetes en essayant d’avoir une vue OPS sur ce sujet. Le principal inconvénient (qui ne l’est pas dans certains cas) des jobs est qu’on ne peut pas les rejouer. Si ces derniers sont terminés avec succès - Vous allez me dire, il faut bien les coder - mais qu’on souhaite les rejouer pour diverses raisons, on doit les supprimer et relancer. J’ai vu plusieurs posts sur StackOverflow à ce sujet, je n’ai pas trouvé de solutions satisfaisantes relatifs à ce sujet.

Attention, je ne dis pas que les jobs et cron jobs ne doivent pas être utilisés. Loin de là.
Je pense que si vous avez besoin d’un traitement sans chaînage d’actions, sans rejeu, les jobs et cron jobs sont de bonnes options. Le monitoring et reporting des actions réalisées peut se faire par l’observabilité mise en place dans votre cluster K8S.
Après plusieurs recherches, je suis tombé sur Spring Data Flow. L’offre de ce module de Spring Cloud va au delà des batchs. Il permet notamment de gérer le streaming via une interface graphique ou via son API.
Dans cet article, je vais implémenter un exemple et le déployer dans Minikube.
1 Installation et configuration de Minikube
L’installation de minikube est décrite sur le site officiel.
Pour l’installer, j’ai exécuté les commandes suivantes:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikubeAu premier démarrage, vous finirez l’installation
minikube start1.1 Installation de Spring Cloud Data Flow
Pour installer Spring Cloud Data Flow directement dans Kubernetes, vous pouvez exécuter les commandes suivantes:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install my-release bitnami/spring-cloud-dataflowAprès quelques minutes de téléchargement, vous devriez avoir le retour suivante à l’exécution de la commande kubectl get pods
kubectl get pods
~ » kubectl get pods
NAME READY STATUS RESTARTS AGE
dataflow-mariadb-0 1/1 Running 1 (24h ago) 24h
dataflow-rabbitmq-0 1/1 Running 1 (24h ago) 24h
dataflow-spring-cloud-dataflow-server-75db59d6cb-lrwp8 1/1 Running 1 (24h ago) 24h
dataflow-spring-cloud-dataflow-skipper-9db568cf4-rzsqq 1/1 Running 1 (24h ago) 24h1.2 Accès au dashboard
Pour accéder au dashboard de Spring Cloud Data Flow, vous pouvez lancer les commandes suivantes:
export SERVICE_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[0].port}" services dataflow-spring-cloud-dataflow-server)
kubectl port-forward --namespace default svc/dataflow-spring-cloud-dataflow-server ${SERVICE_PORT}:${SERVICE_PORT}Ensuite, vous pourrez accéder à la console web via l’URL http://localhost:8080/dashboard.
2 Développement d’une Task
J’ai crée une simple task qui va rechercher la nationalité d’un prénom. Pour ceci, j’utilise l’API https://api.nationalize.io/.
On passe un prénom en paramètre et on obtient une liste de nationalités possibles avec leurs probabilités.
Vous trouverez les sources de cet exemple sur mon Github.
Aussi, la documentation est bien faite, il suffit de la lire.
2.1 Initialisation
J’ai initié un projet Spring avec les dépendances suivantes:
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.cloud:spring-cloud-starter-task'
developmentOnly 'org.springframework.boot:spring-boot-devtools'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
runtimeOnly 'org.mariadb.jdbc:mariadb-java-client'
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}Attention, les starters et dépendances JDBC/MariaDB sont indispensables pour que votre tâche puisse enregistrer le statut des exécutions.
2.2 Construction de la tâche
Une tâche se crée facilement en annotation une classe “Configuration” par l’annotation @EnableTask
@Configuration
@EnableTask
public class TaskConfiguration {
...
}Ensuite l’essentiel du job s’effectue dans la construction d’un bean CommandLineRunner :
@Bean
public CommandLineRunner createCommandLineRunner(RestTemplate restTemplate) {
return args -> {
var commandLinePropertySource = new SimpleCommandLinePropertySource(args);
var entity = restTemplate.getForEntity("https://api.nationalize.io/?name=" + Optional.ofNullable(commandLinePropertySource.getProperty("name")).orElse("BLANK"), NationalizeResponseDTO.class);
LOGGER.info("RESPONSE[{}]: {}", entity.getStatusCode(), entity.getBody());
};
}Dans mon exemple, j’affiche dans la sortie standard le payload de l’API ainsi que le code HTTP de la réponse.
Voici un exemple d’exécution :
2022-08-12 15:11:07.885 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2022-08-12 15:11:07.894 INFO 1 --- [ main] i.t.b.cloudtask.CloudTaskApplication : Started CloudTaskApplication in 17.704 seconds (JVM running for 19.18)
2022-08-12 15:11:10.722 INFO 1 --- [ main] i.t.batch.cloudtask.TaskConfiguration : RESPONSE[200 OK]: NationalizeResponseDTO{name='Alexandre', countries=[CountryDTO{countryId='BR', pr....2.3 Packaging
Ici rien de nouveau, il suffit de lancer la commande:
./gradlew build3 Déploiement
3.1 Création et déploiement de l’image Docker
Pour déployer notre toute nouvelle tâche, nous allons d’abord créer l’image Docker avec buildpack.
Tout d’abord on va se brancher sur minikube pour que notre image soit déployée dans le repository de minikube
eval $(minikube docker-env)Ensuite, il nous reste à créer l’image Docker
./gradlew bootBuildImage --imageName=info.touret/cloud-task:latestPour vérifier que votre image est bien présente dans minikube, vous pouvez exécuter la commande suivante:
minikube image ls | grep cloud-task
info.touret/cloud-task:latest3.2 Création de l’application
Avant de créer la tâche dans l’interface, il faut d’abord référencer l’image Docker en créer une application:
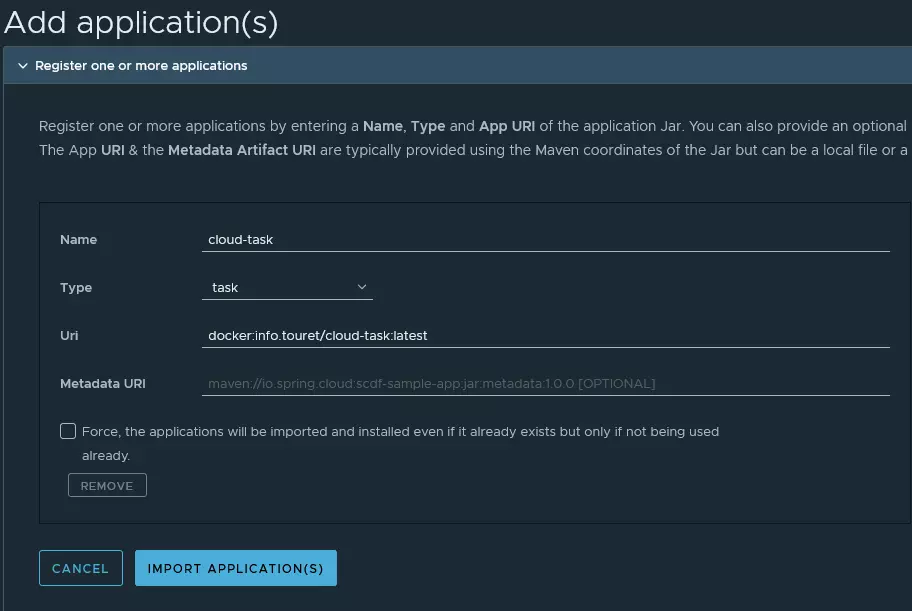
Il faut déclarer l’image Docker avec le formalisme présenté dans la capture d’écran.
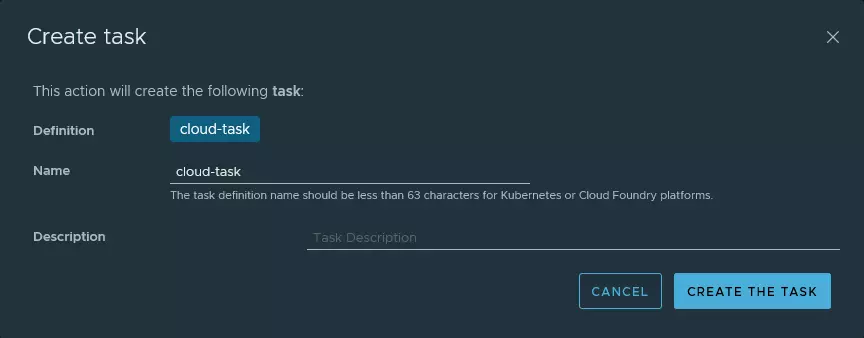
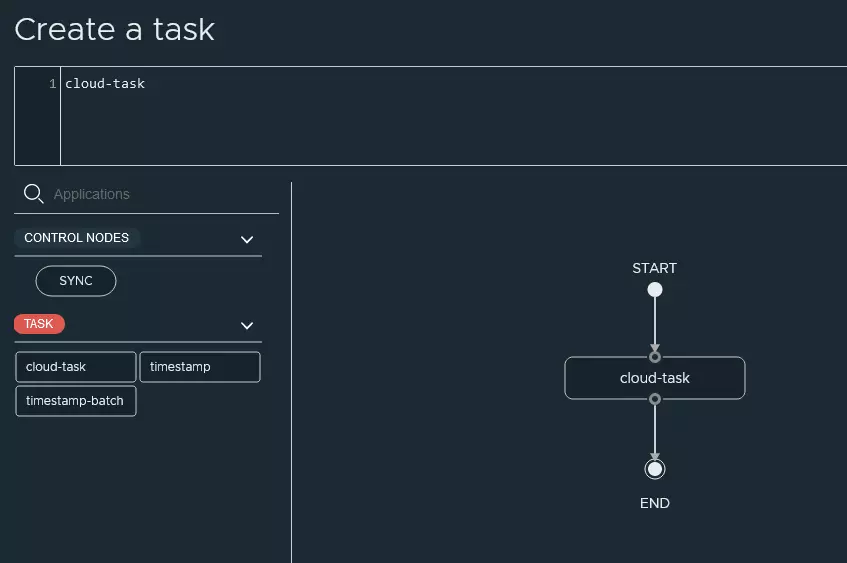
3.3 Création de la tâche
Voici les différentes actions que j’ai réalisé via l’interface:
4 Exécution
Maintenant, il nous est possible de lancer notre tâche. Vous trouverez dans les copies d’écran ci-dessous les différentes actions que j’ai réalisé pour exécuter ma toute nouvelle tâche.
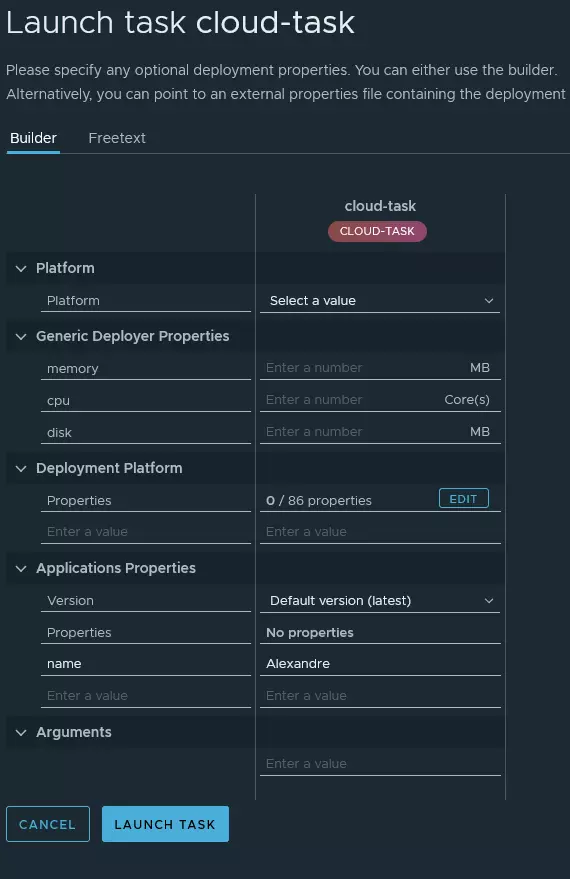
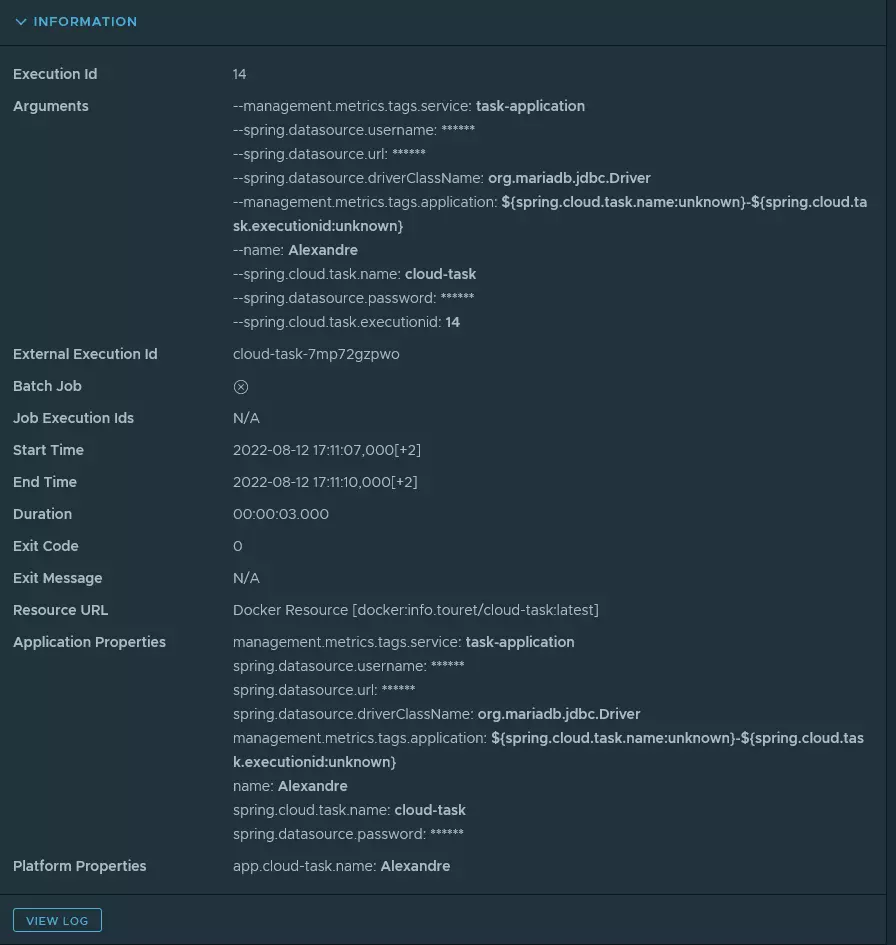
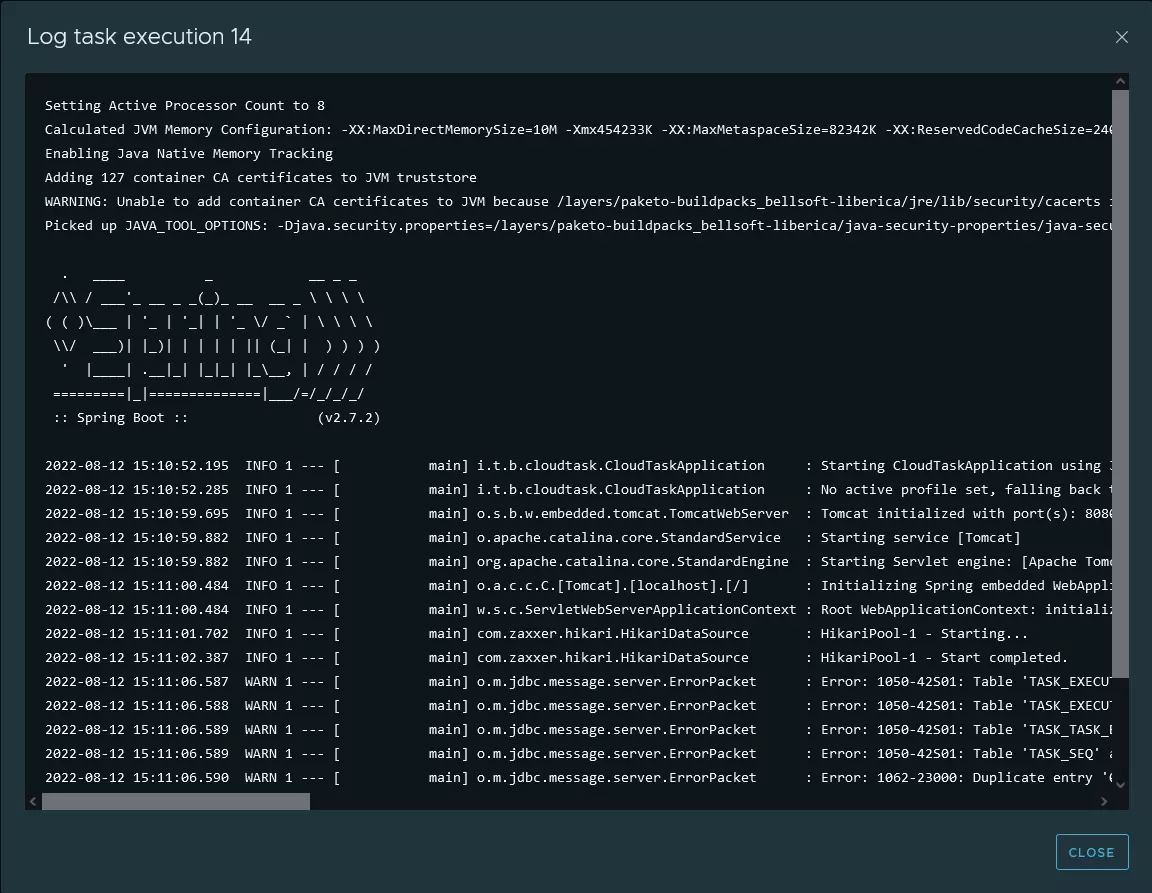
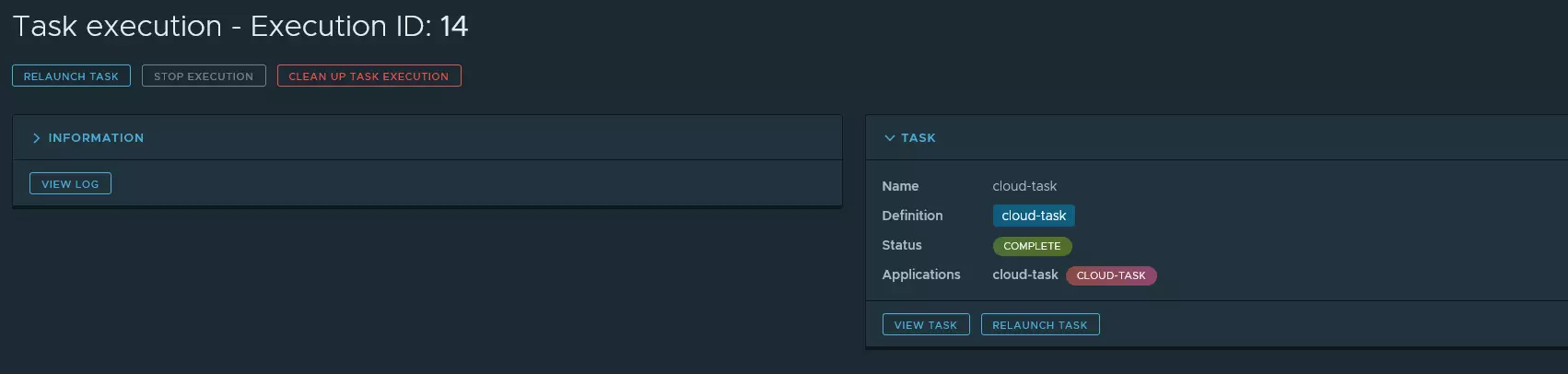
J’ai pu également accéder aux logs.
Il est également important de noter qu’ après l’exécution d’une tâche, le POD est toujours au statut RUNNING afin que Kubernetes ne redémarre pas automatiquement le traitement.
kubectl get pods | grep cloud-task
cloud-task-7mp72gzpwo 1/1 Running 0 57m
cloud-task-pymdkr182p 1/1 Running 0 65mA chaque exécution il y aura donc un pod d’alloué.
5 Aller plus loin
Parmi les fonctionnalités que j’ai découvert, on peut :
- relancer un traitement
- le programmer
- nettoyer les exécutions
- les pistes d’audit
- le chaînage des différentes tâches
Gros inconvénient pour le nettoyage: je n’ai pas constaté un impact dans les pods alloués.
6 Conclusion
Pour résumer, je vais me risquer à comparer les deux solutions jobs/cron jobs Kubernetes et une solution basée sur Spring Cloud Dataflow. Je vais donc utiliser la liste des caractéristiques présentée par M. Richards et N. Ford dans leur livre: Fundamentals of Software Architecture1.
Bien évidemment, cette notation est purement personnelle. Vous noterez que selon où on positionne le curseur, l’une des deux solutions peut s’avérer meilleure (ou pas).
Bref, tout dépend de vos contraintes et de ce que vous souhaitez en faire. A mon avis, une solution telle que Spring Cloud Dataflow s’inscrit parfaitement pour des traitements mixtes (streaming, batch) et pour des traitements Big Data.
N’hésitez pas à me donner votre avis (sans troller svp) en commentaire ou si ça concerne l’exemple, directement dans Github.
| Architecture characteristic | K8s job rating | Spring Cloud Dataflow rating |
|---|---|---|
| Partitioning type | Domain & technical | Domain & technical |
| Number of quanta 2 | 1 | 1 to many |
| Deployability | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Elasticity | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Evolutionary | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Fault Tolerance | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Modularity | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Overall cost | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| Performance | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Reliability | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| Scalability | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Simplicity | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Testability | ⭐⭐⭐ | ⭐⭐⭐⭐ |