Mieux analyser les risques pour simplifier les architectures (ou pas)

1 L’analyse des risques: kezako ?
Souvent utilisée dans la prise de décision, l’analyse des risques a plusieurs objectifs :
- Permettre de pondérer des risques potentiels
- Faciliter la prise de décision sur les actions à réaliser pour les prévenir ou tout du moins les atténuer.
Mais d’abord, revenons aux bases. Comment identifier un risque ?
Selon Wikipedia, voici la définition:
Le risque est la possibilité de survenue d’un événement indésirable, la probabilité d’occurrence d’un péril probable ou d’un aléa.
Bien évidemment, on a les risques inconnus et ceux qui sont connus. Le préalable à toute gestion de risque (tout du moins pour la définition d’architecture) est de capitaliser les connaissances et retours d’expérience qui viennent du terrain.
On va donc oublier les risques inconnus dans cet article.
1.1 Comment les définir ?
Tout d’abord, il faut connaître les SLOs de la plateforme qu’on souhaite concevoir. Pourquoi ? Pour vérifier si les risques qu’on identifiera plus tard sont pertinents ou tout du moins impactants.
Par exemple: Une panne électrique sera faiblement impactante pour une application avec une disponibilité < 70%.
La réalisation des SLIs et SLOs est un préalable pour définir le “budget d’erreur”. Ce dernier nous permettra in fine de quantifier les risques et de voir si il faut les atténuer.
Ensuite, pour chaque risque qu’on identifiera (souvent à partir de notre expérience), on tâchera de définir les caractéristiques suivantes:
- Cause
- Probabilité
- Conséquence (gravité)
1.1.1 Un exemple
La base de données est indisponible
- Cause: Système de fichier plein
- Probabilité: faible
- Conséquence: forte (toute la plateforme est HS)
Pour déterminer la cause, il y a plusieurs méthodes, l’une des plus célèbres est celle des cinq pourquoi.
Elle permet d’accéder à la cause du problème.
Pour établir la probabilité, les OPS seront vos meilleurs ami.e.s. Vous remontrez dans le temps pour déterminer quels ont été les différents incidents. Pour chacun, vous devrez définir ces trois caractéristiques : cause, probabilité, conséquence.
A coté de ça, vous aurez à identifier si possible le temps d’indisponibilité du service.
1.2 Synthèse
Une fois ce travail de fourmi réalisé, vous pourrez le synthétiser dans un premier temps avec ce formalisme souvent repris dans la gestion de projet:
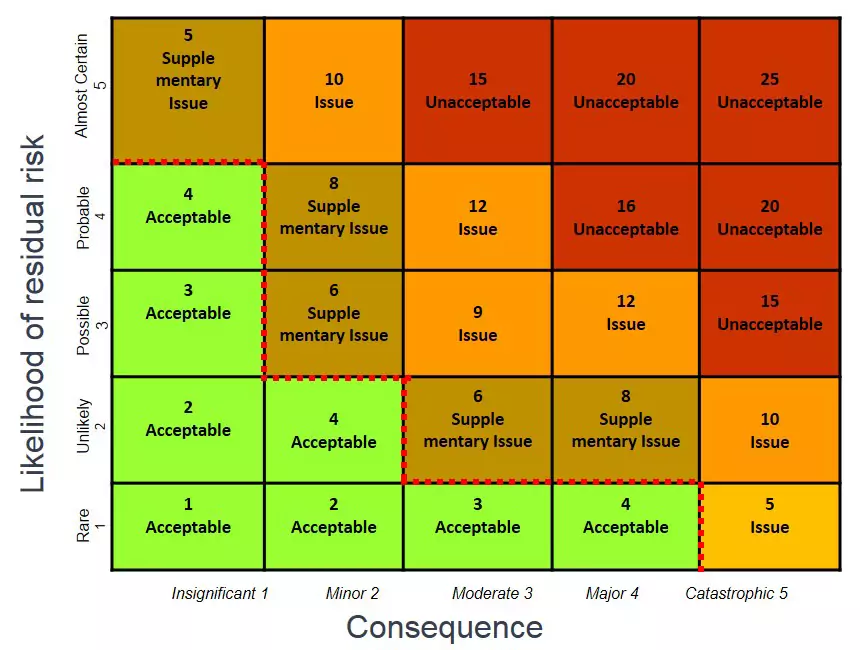
En résumé, les actions qui sont oranges ou rouges doivent être traitées et avoir un plan d’action.
Prenons la définition d’une plateforme: Si votre API doit traiter de manière régulière des PAYLOADs volumineux (bon déjà, la ce n’est pas top). Le temps de traitement peut être très long et bloquer certaines ressources (ex. des sous transactions).
Dans ce cas, la probabilité sera à probable et l’impact sera modéré ou majeur. Par conséquent, vous devrez le prendre en compte avec par exemple un circuit breaker.
Pour aller encore plus loin, vous pouvez également évaluer les risques en fonction de votre budget d’erreur: Est-ce que l’erreur peut rentrer dans mon budget ou pas? Bref, est-ce acceptable?
Si vous allez plus loin, je vous conseille la formation Coursera Site Reliability Engineering: Measuring and Managing Reliability.
2 OK, j’ai identifié les risques potentiels. Qu’est-ce que j’en fait maintenant?
C’est là que démarre réellement le travail d’architecture: vous devrez évaluer chaque risque en fonction des exigences fonctionnelles et technique pour savoir si elles valent la peine d’être prises en considération. Si vous avez des risques de faible impact, vous pourrez soit les “mettre sous contrôle” pour traiter d’autres problèmes, soit les traiter car ils sont “faciles” à traiter et vous permettront d’agrandir votre “budget d’erreur”. Dans ce dernier cas, vous aurez la possibilité de laisser “de coté” d’autres erreurs plus compliquées à traiter car elles rentreront dans votre budget.
Bref, c’est un vrai travail de fourmi qui se base sur l’expérience du terrain.
3 Quid de l’architecture?
Si vous avez évalué les risques correctement, vous pourrez ne traiter que les risques qui en valent la peine et par conséquent n’ ajouter de la complexité que là ou ça en vaut la peine!
Oui, ce travail préalable permet de faire simple!
4 Un exemple concret
Si je reprends l’application bookstore que j’ai décrite dans un précédent article:
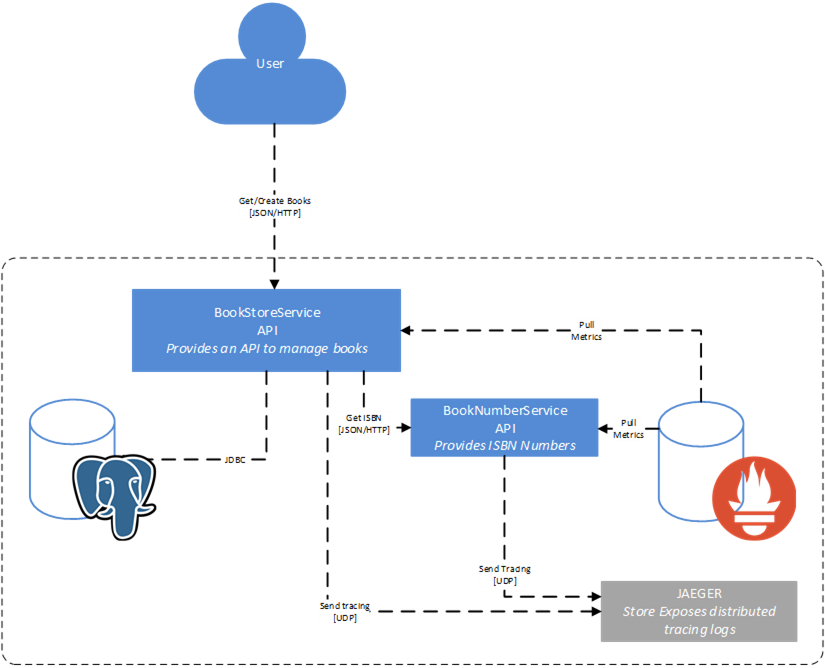
4.1 Exigences techniques
4.1.1 SLOs / SLIs
Pour cet exemple, je ne vais traiter que deux exigences techniques:
| SLO | SLI |
|---|---|
| L’API Bookstore doit être disponible 99% | Nombre de réponses HTTP = 2XX ou 4XX |
| L’API Bookstore doit répondre en moins de 1 sec | Temps de réponse de l’API |
4.1.2 Volumétrie
- 100 transactions par seconde (TPS)
- 100 utilisateurs simultanés
4.2 Risques identifiés
Sans aller dans le détail, voici quelques risques que l’on peut identifier de prime abord dans cette architecture:
- Indisponibilité du service bookstore
- Indisponibilité du service booknumber
- Indisponibilité de la base de données à cause d’une forte volumétrie
En vous basant sur l’expérience de vos OPS, vous pourrez également ajouter des risques liés à l’infrastructure (routeurs, DNS, …). Je ne vais pas les aborder dans cet article.
4.3 Qualification des risques
Voici une rapide qualification:
| Risques | Probabilité | Impact |
|---|---|---|
| Indisponibilité du service bookstore | Probable | Majeur |
| Indisponibilité du service booknumber | Probable | Majeur |
| Indisponibilité de la base de données | Possible | Catastrophique |
Si on se réfère au premier diagramme, il est obligatoire de les prendre en compte.
4.4 Solutions d’architecture pour leur prise en compte
Une fois les risques identifiés, on peut tout d’abord les confronter à notre budget d’erreur pour valider leur prise en compte dans notre conception.
Dans notre cas, on va prendre le postulat qu’il faut réellement les prendre en considération et trouver une solution adaptée.
Voici des exemples de solutions qui permettraient de faire descendre leur impact our leur probabilité.
| Risques | Probabilité | Impact | Action/Solutions possibles |
|---|---|---|---|
| Indisponibilité du service bookstore | Possible | Majeur | Load balancing avec deux instances, Utilisation Kubernetes,. |
| Indisponibilité du service booknumber | Possible | Majeur | Sur le service book-number: Load balancing avec deux instances, Utilisation Kubernetes,.. Sur le service bookstore: Mettre en place un circuit breaker basé sur le timeout d’appel vers le service book-number pour garantir la SLO |
| Indisponibilité de la base de données | Possible | Catastrophique | - Réalisation d’un benchmark pour s’assurer qu’une instance est suffisante. - Sinon mise en place mécanisme HA ou changement de technologie |
5 Conclusion
L’analyse des risques n’est pas récente et n’a pas été inventée par le monde de l’informatique. Elle est d’abord apparue dans la gestion de projets et fait désormais partie prenante de la définition d’architectures (enfin ça commence…). Il ne faut pas la voir seulement pour un outil de “GO-NO GO” de réunion de cellule de crise mais comme une aide à la décision pour la conception des systèmes.
Il a toute sa place à coté des différentes caractéristiques que vous devrez prendre en compte ( sécurité, modularité, …). J’ai essayé de décrire comment les identifier et trouver une solution adaptée dans l’exemple. Bien évidemment, il n’est pas complet. Je pense néanmoins qu’il permet d’avoir une idée sur le sujet.
Le principal avantage d’utiliser à la fois les SLOs/SLIs, le budget d’erreur et l’analyse des risques est de n’apporter de la complexité que là où c’est nécessaire.
Pour certains un benchmark sera souvent utile pour confirmer votre décision.
Si vous voulez aller plus loin, je vous conseille dans un premier temps de lire “Fundamentals of Software Architecture”. Ce sujet y est abordé.
Enfin,si ce sujet vous intéresse, vous pouvez vous projeter au délà de l’informatique en lisant les analyses de risques réalisées par le Ministère des finances.
Bonne lecture ;-)